この記事の要点
- OpenCVは画像処理関連のライブラリの中でも物体検出(画像認識)を行える点が大きな特徴
- PythonとOpenCVを使い、実際に顔検出をやってみる
- 自分のスキルとやりたいことを明確にして、書籍を選んでみよう
以前、Pythonで初心者が作れるもの5つのうちの1つとして画像認識について紹介していました。
今回は、画像検出・画像認識のライブラリであるOpenCVの基本的な使い方や機能などを通してPythonの応用的な使い方を解説していきます。
内容が人工知能関連で難しそうですが、初心者にもわかりやすいシンプルなコードを掲載しましたので、是非ゆっくりと読み進めてください。
目次
OpenCVとは?
OpenCVは画像や動画処理を目的とするライブラリの一つです。
名前からも分かる通り、ソースコードを無償で一般公開しているオープンソースで、世界中のプログラマによって継続的に改良が続けられます。
画像処理関連のライブラリの中でもOpenCVは物体検出(画像認識)を行える点が大きな特徴だと言えます。
今回はこの物体検出をPython初心者向けにわかりやすく解説します。
OpenCVの主な機能
OpenCVでは主に以下のことを実装できます。
- 画像や動画の読み込み, 表示, 保存
- 数値から画像ファイルの生成
- 画像処理(拡大, 縮小, 回転, 反転...)
- 物体検出(画像認識)
いくつかの機能をプログラムを含めて見てみましょう。
何度も記載すると複雑になりますので、機能を示すコードのみを記載します。
それぞれ独立したコードではなく、変数も共通していると考えてください。
# ライブラリのインポート import cv2 # exという名前のウィンドウを生成する cv2.namedWindow(“ex”, cv2.WINDOW_NORMAL) “”” ここに処理を書く “”” # キー入力を待つ 単位はms(1000ms = 1秒間) cv2.waitKey(3000) # ウィンドウを閉じる cv2.destroyWindow(“ex”)
今回は”ex”という名前のウィンドウを生成します。(自由に変更可能)
“””で囲まれた部分に画像の処理内容を記述するといった認識で構いません。
cv2.waitKeyでのキー入力を待つことで処理が進みます。
この例では3秒間ウィンドウを表示して自動的に閉じます。
画像を出力するだけであればウィンドウを生成する必要はありません。
これだけでは画像の読み込みや表示を行えていません。
それぞれの処理を順番に見てみましょう。
※ 以下の処理は”””内に記述するものとします。
画像の読み込み・表示
画像処理を行うには対象となる画像を読み込み、表示する必要があります。
今回は例として、フォルダ内にあるApple.pngという画像ファイルを取り扱いましょう。
# 画像ファイルを読み込む
img = cv2.imread(".../Apple.png"))
# exに読み込んだ画像(img)を表示する
cv2.imshow("ex", img)
注意点として、画像パスを絶対パスにしなければ読み込まれない場合があります。
以下、使用する画像をimgとし、画像を表示するコードがあるものとします。
グレイスケールでの読み込み
画像を白黒として読み込みたい場合に便利な方法があります。
# 白黒で読み込み img = cv2.imread(“.../Apple.png”, cv2.IMREAD_GRAYSCALE)
imreadの第2引数にcv2.IMREAD_GRAYSCALEを指定すると簡単に白黒画像として読み込むことができます。
細かいアルゴリズムを知る必要はありませんが、他にも白黒の指定方法があるので気になる方は調べてみてください。
画像の書き込み
処理した画像を保存する方法をご紹介します。
グレイスケールでの読み込みで使用したimgを保存したい場合
# imgをAppleGray.pngという名前で保存 cv2.imwrite(“.../AppleGray.png”, img)
このようにしてOpenCVでは画像を取り扱います。
「参考」
https://opencv.org/
OpenCV公式サイト
https://www.klv.co.jp/corner/python-opencv-what-is-opencv.html
【Python×OpenCV】初めてのOpen CV(画像処理ライブラリ)ガイド
Pythonと OpenCVを使った顔検出の流れ
検出のための準備
顔検出にもいくつかの種類があります。
OpenCVではすでに学習済みのデータがあり、それを利用すると比較的簡単に実装できます。
データはライブラリのインストール方法によって異なるため、今回はGithub上のファイルをダウンロードして検出を行いましょう。
「参考」
https://github.com/opencv/opencv/tree/master/data/haarcascades
検出用のデータ(GitHub)
「.../data/haarcascades/」にxmlファイルが用意されています。
例えば以下のようなデータがあります。
- 目を検出: haarcascade_eye.xml
- 笑顔を検出: haarcascade_smile.xml
- 正面の顔を検出: haarcascade_frontalface_default.xml
目的に応じて使用するxmlファイルを選びましょう。
シンプルな実装
今回はPerson.jpgから目の検出を行い、目を緑色の枠で囲むサンプルプログラムです。
#インポート
import cv2
# xmlファイルを読み込む
eye_classifier = cv2.CascadeClassifier(".../haarcascade_eye.xml")
# 画像ファイルを読み込む
img = cv2.imread(".../Person.jpg")
# グレイスケールの画像に変換する
img_gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 読み込んだ画像から目の取得
eyes = eye_classifier.detectMultiScale(img_gray)
# 検出した目に対する処理
for (x, y, w, h) in eyes:
# 目の周りにrgb(0, 255, 0)色の枠を描画する
cv2.rectangle(img, (x, y), (x + w, y + h), (0, 255, 0), 2)
# 画像の出力
cv2.imwrite(".../Person_eye.png", img)
プログラムの解説を簡単にすると、検出のためのxmlデータを取得し、Person.jpgを読み込みます。
検出のために画像をグレイスケールに変換します。今回は後からimgに枠を描画します。
そのため、imgを残しておきたいので、新しい変数img_grayを用意しました。
次に、実際にeye_classifier.detectMultiScale(img_gray)で白黒画像から目の検出を行います。
この時の返り値は複数の目が検出される場合を考慮し、配列となっています。
得られた目の情報をfor文でそれぞれ処理しましょう。(x, y, w, h)は(x座標, y座標, width(横幅), height(縦幅))を示しています。
この情報をもとにrectangle関数でimgに四角形を目の位置に描画します。
最後にimgをパスを指定し、出力します。
出力に指定したパスを確認すると目の検出が行われた画像が保存されていると思います。
もし、何も変化のない場合は目が検出されなかったことになります。len(eyes)で検出した目の個数を出力しても確認できますね。
「参考」
https://docs.opencv.org/trunk/d7/d8b/tutorial_py_face_detection.html
公式の顔検出チュートリアル
顔検出がうまくいかないケース
学習済みのモデルが完璧だとは限りません。
検出ができない場合も多々あります。
例えば、目の検出で画像の顔が斜めになっている場合に検出できない場合だとモデルが斜めの顔を学習できていないことを表しています。
この時には画像を斜めにして顔を真っ直ぐにするといった対策が可能ですが、あまり実用的ではありません。
例として、photoACさんから素敵な男性の顔を使用させていただきます。

この画像を先ほどのプログラムを使って、目の検出を行うと次のようになりました。
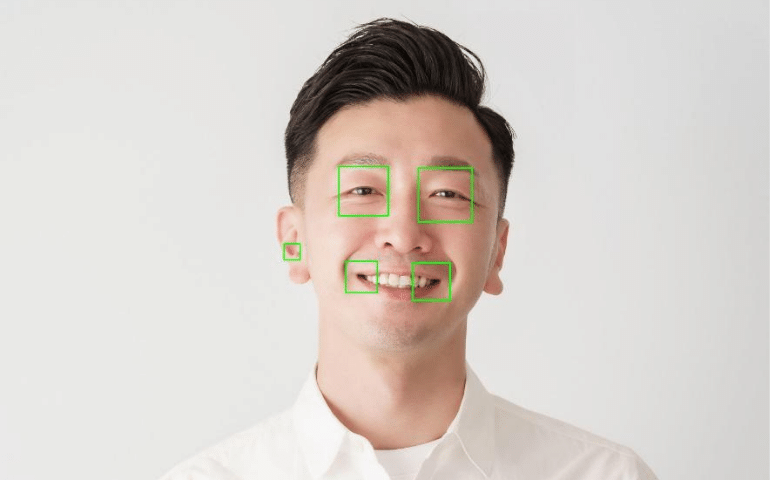
しっかりと目の検出はできましたが、口や耳までもが目だと検出されてしまいました。
このようにうまくいかない場合にはさまざまな要因が考えられますが、xmlファイルのデータ自体が有効的ではない場合も考えられます。
これを理解するには人工知能の仕組みをお話しする必要がありますが、とても複雑なので今回は省略します。
GitHubのアップロード時期からもわかりますが、少し古いファイルです。
そのため、あまり精度は高くないとも考えられます。
Pythonの画像検出やOpenCVの学習におすすめの書籍
レベルごとにオススメする本の内容は異なります。
自分のスキルとやりたいことを明確にして、書籍を選んでみましょう。
OpenCVによる画像処理入門

Pythonを含む、いくつかの言語でOpenCVを学習でき、画像処理の基本が身につきます。
初心者でもわかりやすく、汎用的な内容を理解できます。
何を学習すればよいかわからない方にはこちらの書籍から始めてみることをお勧めします。
OpenCVによるコンピュータビジョン・機械学習入門

コンピュータビジョンは「コンピュータがデジタルな画像や動画をいかによく理解できるか」を取り扱う研究分野です。
機械学習は人工知能のことだと捉えても構いません。
つまり、OpenCVでの人工知能を用いた画像認識を専門とする書籍になります。
ゼロから作るDeep Learning

画像認識は人工知能の分野になります。
そのため、深く理解したい方は人工知能の本を読んでみてはいかがでしょうか。
偏微分や逆誤差伝播法といった難解なアルゴリズムが記載されているため、数学的な知識が必要になります。
しかしながら内容はとても専門的で実用的なもので、世界中の研究者から人気があります。
「プログラミングは初心者だけど、数学なら得意」や「人工知能を本気で理解したい」という方にオススメできる本です。
書籍だけだと理解できないと感じる方にはスクールも検討してみましょう。
テックジムは定額制のプログラミング教室です。無料オンラインで「ゼロから始めるPythonプログラミング入門講座」を学ぶことができます。
ゼロから始めるPython入門講座(オンライン・無料)+【テックジム】
![]()
またテックアカデミーは、現役エンジニアから学べるところがポイントです。学習後に必ずお仕事を紹介しれくれるので、学習から実践まで一気に取り組むことができます。
そのほかに、Winスクールは一人ひとりに合わせた学びを、直接指導でサポートしてくれます。初心者から経験者まで、さまざまなレベルやニーズに合わせた丁寧な指導を受けることができます。
まとめ
PythonとOpenCVを用いた目の検出を実際に行いましたが、いかがだったでしょうか?
画像認識は人工知能の分野なので複雑で初心者には到底不可能な分野だと感じてしまいそうですが、今回のように意外とシンプルなコードで簡単に実装できます。
このライブラリを用いて、いろんな機能に応用してみると面白いと思います。
とはいえ、画像認識を行うため初心者にとっては難しい内容になります。
何度か読み返し、コードに変化を加えているといつの間にか理解できるようになります。
おすすめしたような書籍を使い、学習することも大切です。
また、画像認識がとっつきにくいかも思った方は、デスクトップアプリや自動化ツールなどもおすすめです。